[ 대규모 서비스를 위한 AWS의 대표적인 NoSQL Database 서비스 알아보기 ]
모던 애플리케이션과 데이터베이스
관계형과 NoSQL 데이터 베이스 (다양한 문제를 해결하기 위해 그 어느 때보다 많은 데이터베이스가 새롭게 등장)
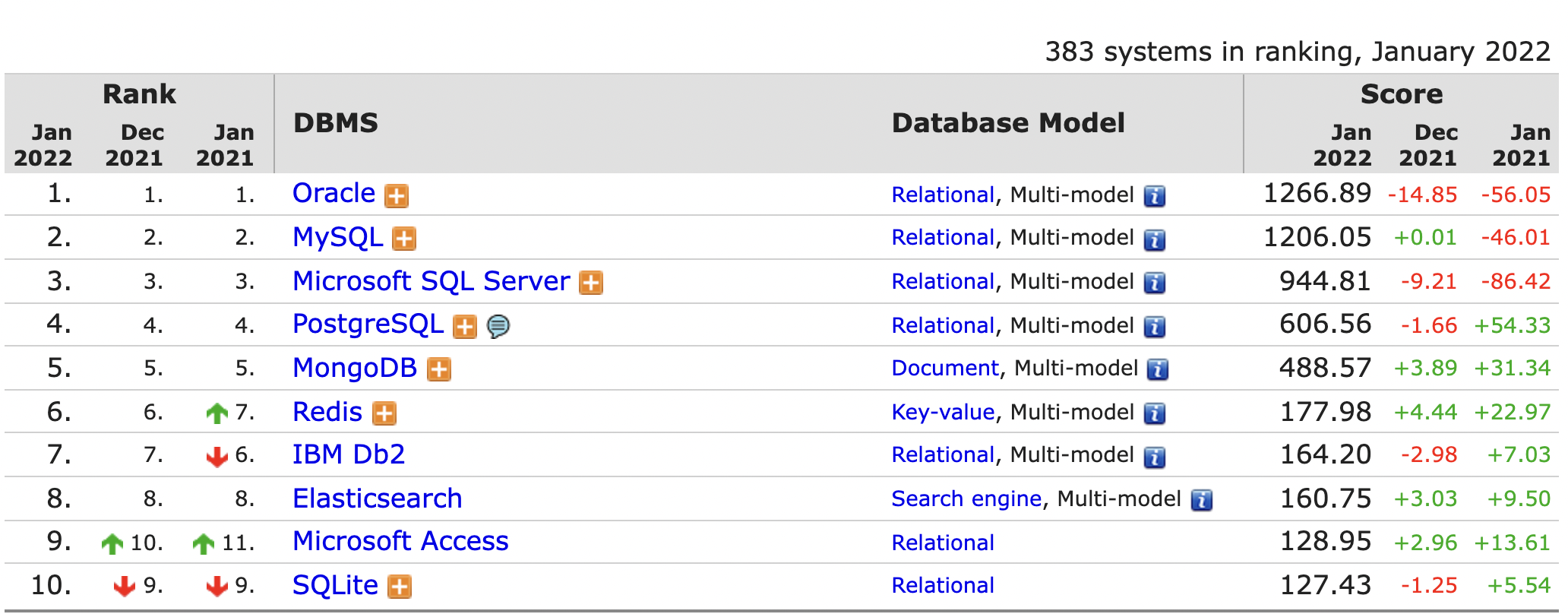
383개의 데이터베이스 엔진이 등록되어 있고, 인기 순위 Top 10에 무려 3개의 NoSQL 데이터베이스가 있는 것을 보실 수 있습니다.
이것이 절대적은 수치는 아닐 수 있지만, 많은 애플리케이션에서 이제는 NoSQL 데이터베이스가 점차 일반적이 되어가고 있다고 예샹해 볼 수 있습니다.
닷컴 버블이 끝나고 인터넷 기업들이 주도하는 4차 산업혁명의 시작과 함께 IT에는 다양한 프로그래밍 언어와 런타임이 생겨났고,
그와 함께 데이터베이스도 역사적으로 어느 때보다 많은 데이터베이스 엔젠이 매년 새롭게 등장하고 있습니다.
관계형 데이터베이스가 독점하던 시장이 인터넷의 발전과 데이터의 폭증으로 NoSQL이라는 새로운 영역을 만들어 냈습니다.
그리고 약 10년이 지난 지금, 관계형과 NoSQL 데이터베이스는 서로가 갖고 있는 장점들을 흡수하며 발전하고 있습니다.
대표적으로 관계형 데이터베이스에서 스키마에서 자유로운 JSOn 데이터 타입이라는 것을 볼 수 있고, 이들은 NoSQL의 장점인 확장성을 흡수해 나가고 있습니다. 또한, NoSQL 데이터베이스들은 관계형 데이터베이스가 갖은 주요 특징인 트랜잭션과 보조 인덱스를 흡수하여 자신들의 단점을 제거해 나가고 있습니다.
오픈소스 데이터베이스 (기업들은 왜 오픈소스 데이터베이스에 주목하는가?)
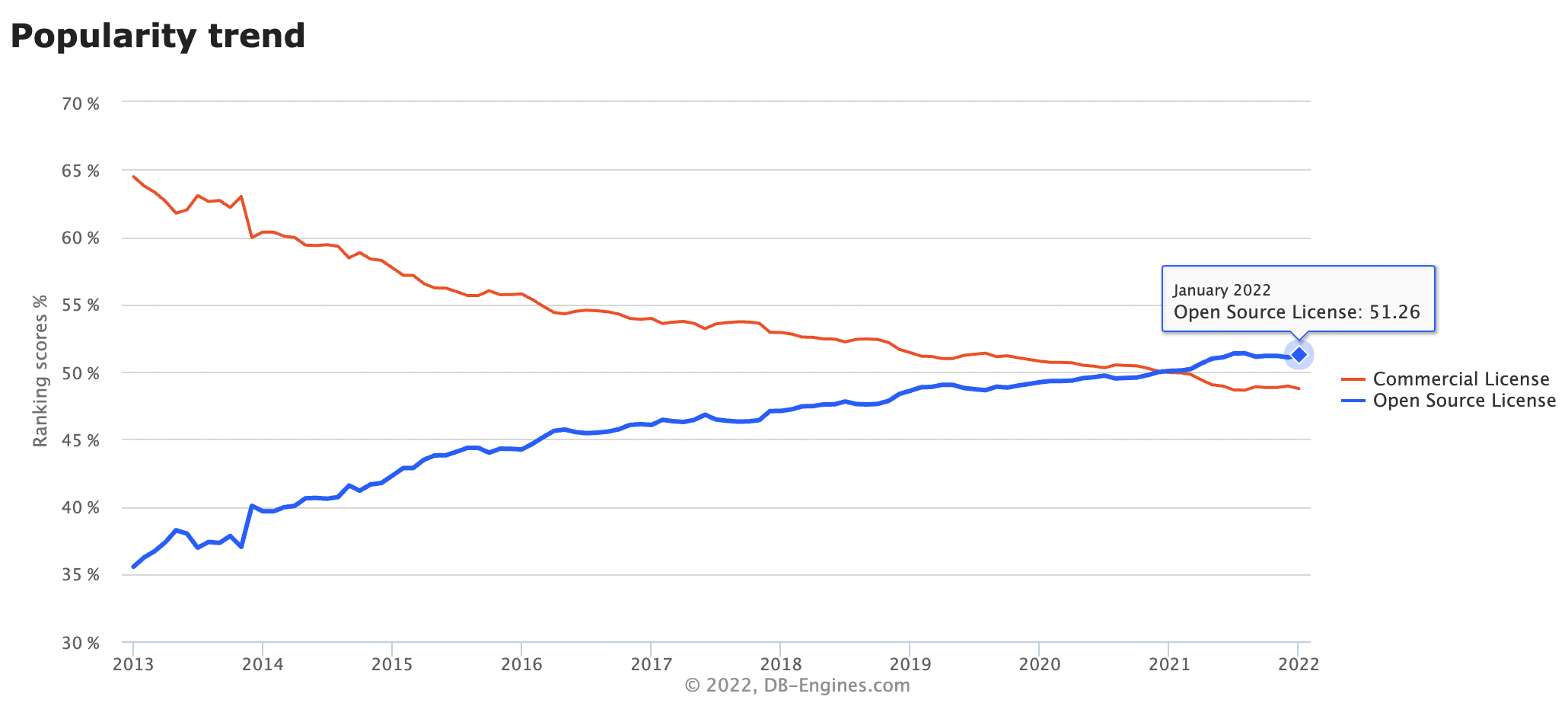
2021년은 역사상 처음으로 오픈소스 데이터베이스가 상용 데이터베이스의 인기를 뛰어넘게 되는 해가 되었습니다.
서비스 스택에서 특정한 이벤트를 위해 몇 시간이나 며칠 단위로 구매할 수 있는 사용 라이센스가 몇 가지나 되겠습니까?
일반적으로 인터넷 상에서 서비스를 제공하는 기업들이라면, 특정 이벤트나 트래픽이 몰리는 피크 시간을 기준으로 충분한 여유분의 사용 라이센스를 미리 구매하고 피크 시간이 지난 후에는 사용하지 않더라도 그 비용을 지불해야 합니다.
그리고 AWS 클라우드의 리소스는 필요에 의해 생성 및 삭제가 언제든 가능하지만, 여러분의 SW가 사용 라이센스에 락인되는 순간 AWS 클라우드의 가장 큰 장점 중 하나인 유연성을 잃어버리게 될 수도 있습니다.
기업들은 오픈소스 데이터베이스를 통해 사용 데이터베이스의 벤더 락인에서 탈출하고, 비용을 절감할 수 있게 됩니다.
그렇기 때문에 많은 기업들이 현재도 오픈소스 데이터베이스로의 마이그레이션을 수행하고 계십니다.
모던 애플리케이션
| 사용자 | 100만 이상 |
| 데이터양 | 테라바이트 ~ 엑사바이트 |
| 성능 | 1/1000 초 ~ 1/1,000,000 초 |
| 요청 량 | 초당 수백만 |
| 접근 | 다양한 디바이스 |
| 확장규모 | 무제한 |
| 지불 방식 | 사용한 만큼 |
| 개발자 접근 | 관리형 API |
인터넷 스케일의 모던 애플리케이션
Amazon Autota - Amazon Fulfilment Technologies(AFT)는 Amazon에서 이루어진 구매에 대해 실제 주문 처리를 지원합니다. PrimeDay에 AFT의 PostgreSQL 호환 버전 Amazon Aurora 인스턴스 3,715개는 2,330 억 건의 트랜잭션을 처리하고 1,595테라바이트의 데이터를 저장하며, 615테라바이트의 데이터를 전송했습니다.
Amazon DynamoDB - DynamoDB는 Alexa, Amazon.com 사이트 및 모든 Amazon 물류 처리 센터 등 트래픽이 많은 다수의 Amazon 시설과 시스템을 지원합니다. 66시간의 Prime Day 기간 동안 이러한 소스는 수조 건의 API 호출을 수행하면서 한 자릿수 밀리초 성능을 통해 고가용성을 유지하고 초당 최대 8,920만 건의 요청을 소화했습니다.
마이크로 서비스 아키텍처
인터넷 스케일의 서비스를 만들기 위해서는 기존의 큰 하나의 덩어리로 이루어진 모노리틱으로는 비지니스의 빠른 속도를 뒷받침하기 어렵습니다. 얼마 전까지만 해도 많은 기업들에서 사용되던 모노리틱 구조의 프로덕션 환경에서 배포가 한 번 이루어지려면 매우 많은 사람들이 연관되어 있었고, 내부의 많은 서비스들이 하나로 패키징되었기 때문에 우선 빌드가 오래 걸리고, 배포는 자주 일어날 수도 없었고, 하루 종일 단체 채팅창을 열어두고 회의실에 모여있을 수 밖에 없었고, 만약 하나의 모듈에서라도 에러를 뱉으면 모두 롤백되고, 예상치 않게 에러를 만든 개발자는 죄인이 되기도 했었습니다.
그와는 반대로 변경에 대한 영향 범위와 위험이 작기 때문에 프로덕션 서비스를 쉽고 빠르게 변경할 수 있는 마이크로 서비스 아키텍처는 빠른 비즈니스 속도를 가능하게 합니다.
여기에서 중요한 점은 모노리틱 구조에선 다수의 서비스가 하나의 대규모 데이터베이스를 공용으로 사용했다면,
마이크로 서비스 구조에선 각 마이크로 서비스 별로 다른 데이터베이스를 사용한다는 것입니다.
그러면 각 데이터베이스를 잘 아는 엔지니어가 조직 내부에 필요하다는 의미이기도 합니다.
단순한 테스트나 소규모의 사용 만이 아니라, 장애 상황을 처리하고 유지/보수도 할 수 있는 그런 엔지니어가 필요합니다.
DevOps
인터넷 스케일과 마이크로 서비스 아키텍처를 지원하기 위해 기업 내 조직은 DevOps 형태로 바뀌어 나가고 있습니다.
각 마이크로 서비스 별로 팀을 구성하고, 각 팀은 스스로 서비스 개발에 대한 것을 결정하며 독립적으로 빠르게 비즈니스의 속도를 낼 수 있는 구조이다.
그런데 현실로 돌아와서 동일한 엔지니어가 이런 마이크로 서비스 아키텍처를 개발도 하고 운영도 해야한다면 어떨까요?
Dev + Ops가 되는 순간, 개발자가 이제 운영까지 한다고 볼 수 있는데요.
Application layer는 일반적으로 데이터를 갖지 않는 Stateless한 성격을 갖기 때문에 가능하지만,
Stateful 성격을 갖는 데이터베이스는 유실되면 서비스의 큰 장애로 이어지며, 그로 인해 규모가 커지면 기업 내 전문 엔지니어들이 필요합니다.
우리의 비지니스는 지금 빠르게 성장하고 있는 중이고, 지금 마이크로 서비스들에서 사용되고 있는 데이터베이스를 잘하는 엔지니어들을 새로 채용하거나, 기존 엔지니어들을 교육해서 서비스에 투입한다? 이게 현실적으로 시간이 오래 걸리고 어렵겠죠.
AWS 클라우드 환경에서는 가능한 많은 완전관리형 서비스를 사용하면서 인프라 운영 부담을 줄이며, 고객은 고객의 핵심 비지니스에 집중하는 것이 가능해집니다.
모노리틱 애플리케이션 대신 마이크로 서비스를 목적에 맞는 도구로 만드세요.
Purpose-built
- 목적에 맞는 데이터베이스를 사용
세단과 트럭이 용도가 다른 것처럼, 각 데이터베이스마다 잘하는 것과 잘 못하는 것이 있기 마련입니다.
그래서 우리는 내 서비스의 목적에 잘 맞는 데이터베이스를 사요앟는 것이 중요합니다.
이를 통해 확장성, 성능 그리고 가용성을 얻을 수 있습니다.
SQL or NoSQL
SQL? NoSQL?
2010년대 초반 NoSQL의 등장과 함께 많은 사람들은 무한하게 늘어날 수 있는 NoSQL을 보며 이제 RDBMS의 시대는 끝났다고 생갔했었습니다. 하지만 최근 트랜드는 둘 중 하나를 고르는 것이 아닌 내 서비스의 워크로드에 맞는 데이터베이스를 골라 사용하는 것이 되었습니다.
SQL, 즉 RDBMS는 현재까지도 많이 활용되는 데이터베이스의 종류입니다. 대부분의 초기 개발은 RDBMS에서 시작되는 경우가 많습니다. SQL과 NoSQL은 각각의 특징이 있으며, 최근 모던 애플리케이션에서는 혼용하여 사용하고 있습니다.
Why NoSQL?
ACID, MVCC, Normalized Table 등 RDBMS가 제공하는 이점보다, 다른 형태(최근 아키텍처)의 요구사항이 커질 경우, RDBMS를 이용한 아키텍처가 도리어 부담으로 작용할 수 있습니다.
| 최근 아키텍쳐 요구 사항 |
| 대용량 데이터 처리 |
| 시계열 처리 |
| 그래프 처리 |
| 개발자들의 가변적 스키마 요구 |
| Document 처리 |
대용량 데이터 처리 - 1
OLTP 형태의 데이터 처리에서는 보통 Write:Read 비율이 1:9 ~ 2:8 수준으로 발생합니다.
이럴 경우 일단 접근할 수 있는 전략은 기존의 RDBMS에 Read Replica를 추가하여, Read 확장성을 이용하는 방법입니다.
대용량 데이터 처리 -2
극단적으로 Read가 많이 발생하는 경우, 아니면 동일한 값을 재활용하는 Cache 전략을 적용할 수 있는 경우, In-memory Database를 추가로 앞에 위치시킬 수 있습니다.
대용량 데이터 처리 - 3
비지니스가 확장될 경우, Primary node에 대한 Write를 초기에는 Scale Up 으로 대치하지만 얼마 지나지 않아 그 한계점에 도달하게 됩니다.
대용량 데이터 처리 - 4
하나의 물리적인 서버가 처리할 수 있는 용량에는 한계가 있음을 인정하고, 여러 개의 물리적인 서버에 분산 저장할 수 있는 Database나 Framework를 도입하게 됩니다.
대용량 데이터 처리 - 5
분산 Database에서 Node의 증가는 바로 운영 비용 및 운영상의 어려움을 마주하게 됩니다.
대용량 데이터 처리 - 6
태생적으로 분산 처리를 고려하여 만든 Database이면서, 대규모 Cluster를 구성해도 안정적인 운영 환경을 제공하는 서비스를 채택하게 됩니다.
AWS의 대표적인 NoSQL 데이터베이스 서비스
Amazon DynamoDB
| 규몽 따른 성능 | 서버리스 | 엔터프라이즈에 사용 가능 |
| 초당 수백만 이상의 요청 처리하도록 확장 가능 | 완전 관리형 | ACID 트랜잭션 |
| 일관된 10밀리초 미만의 성능 | Auto scaling | 저장 중 암호화 |
| 다중 리전 복제 자동화 | 온디맨드 모드 | 특정 시섬으로 복구(PITR) |
| Kinesis Data Streams for DynamoDB로 고급 스트리밍 애플리케이션 개발 | 트리거를 사용한 변경 추적 | 온디맨드 백업 및 복구 |
페타바이트 규모에서도 10밀리초 미만의 성능 (규모에 따른 성능)
- 초당 수백만 이상의 요청
- 수 조 이상의 아이템
- 페타바이트 이상의 스토리지
- 10밀리초 미만의 쓰기/읽기 성능
전역 테이블을 사용하여 전역 복제 자동화 (규모에 따른 성능)
- 글로벌로 분산된 고성능 애플리케이션을 제작
- 동일 리전 내 가능한 테이블로 저 지연 읽기 및 쓰기
- 다중 리전 중복을 통한 99.999% 가용성
- 모든 리전에서 쓰기 가능
- 간단한 설정과 애플리케이션 변경 없음
고객의 비즈니스를 위한 소중한 시간 돌려드리기 (서버리스)
| 보안 | 가용성 | 성능 | 내구성 | 확장성 |
| 운영체제 패치 | 고가용성 설정 | 성능 튜닝 | 서버, 랙 및 데이터 센터 장애 대비 |
Host 제공 |
| 데이터베이스 패치 | 모니터링 | 인덱스 | 하드웨어 장애 시 신속하게 데이터 재복제 | Host 복구 및 정리 |
| 심사 | 리전 간 복제 | In-memory 캐싱 | 백업 및 복원 관리 | |
| 암호화 | ||||
| 규정 준수 |
프로비저닝 용량 모드 : 자동 크기 조정, 성능 유지 (서버리스)
- 자동화된 확장 정책
- 필요 시 확장
- 필요 없을 시 축소
- 스케줄에 따른 크기 조정
온디맨드 용량 모드 : 빠르고 유연한 확장 (서버리스)
- 용량 관리 불필요 : 얼마만큼의 읽기/쓰기 처리량을 사용할 지 예측할 필요 없음
- 예측 불가능한 워크로드에 최적화 : 요청 시 초당 0에서 수만 요청까지 자동으로 증가
- 사용한 만큼만 지불 : 요청당 지불 가격
ACID 트랜잭션에 대한 서버 측 지원 (엔터프라이즈에 사용 가능)
- ACID 보장으로 애플리케이션 코드 간소화
- 대규모 워크로드에 대한 트랜잭션 실행
- 레거시 마이그레이션 가속화
백업 및 복원 (엔터프라이즈에 사용 가능)
- 장기 데이터 보관 및 규정 준수를 위한 온디맨드 백업
- 특정 시점 복구(PITR)를 위한 연속 백업
- 성능에 영향을 미치지 않고 즉시 PB 단위의 데이터 백업
Amazon ElasticCache (Redis 또는 Memcached와 호환도니느 완전 관리형 인 메모리 데이터 스토어)
- Redis & Memcached 호환 : 오픈소스 Redis and Memcached와 호환
- 탁월한 성능 : 1밀리초 미만의 응답시간이 필요한 애플리케이션을 위한 인 메모리 데이터 스토어
- 보안 및 안정성 : VPC 지원, 전송 및 저장 중 암호화, HIPPA, PCI, FedRAMP, 다중 가용 영역, 자동 장애 조치
- 간편하게 확장 가능 : 샤딩과 리플리카로 읽기와 쓰기 확장
Memcached
고객의 서비스가 String 및 Object의 간단한 데이터 타입만을 사용하며, 고 가용성이 불필요한 경우
Redis
String, List, Set 등 개발자의 생산성을 높일 수 있는 다양한 빌트인 데이터 타입과 고가용성, 그리고 샤딩 및 복제를 통해 읽기/쓰기 확장성이 필요할 때
Redis는 일반적으로 애플리케이션들이 공용으로 사용할 수 있는 세션스토어, 데이터베이스의 트래픽 부담을 덜기 위한 캐싱, 실시간 랭킹보드 등에 사용할 수 있습니다.
Redis란? (인메모리 데이터 스토어, 키-값 데이터베이스)
개발자들이 Redis를 사랑하는 이유
1. Blazing fase
2. 다양한 자료 구조
3. Feature rich and easy to use
4. 오픈소스
자체 관리 Redis는 어렵고 시간 소모적입니다.
- 관리가 어려움 : 서버 프로비저닝 소프트웨어 패치, 구성 및 백업 관리. 매력적인 고객 경험을 구축하는데 더 많은 시간을 할애할 수 있음
- 고가용성 구축의 어려움 : 빠른 오류 감지 및 수정 구현 필요
- 확장의 어려움 : 온라인 확장은 오류가 발생하기 쉬우며 복제 성능을 모니터링 해야 함
- 고 비용 : 사람, 프로세스, 하드웨어 및 소프트웨어에 투자해야함. 실시간 수요에는 종종 엄청난 스파이크가 발생함
Amazon ElastiCache Redis (AWS의 모든 기능을 기반으로 구축)
- 모든 AWS 리전에서 사용 가능
- Multi-AZ 자동 장애 조치
- 글로벌 데이터스토어 : 리전 간 복제
- 클러스터 당 최대 500 노드
- 최대 340TB 용량
- T2, M5, R5, M6[G], R6[G] 타입 지원
- 예약된 스냅샷 지원
- 스케일 아웃/인
- 스케일 업/다운
글로벌 데이터스토어(리전 간 복제)
- 기존 클러스터의 원클릭 설정
- 로컬에서 쓰고, 글로벌로 읽기 가능
- 리전 간 재해 복구 활성화
- Redis의 밀리초 미만 지연 시간으로 극한의 성능 활용
- 교차 리전 트래픽에 대한 전송 중 보안 암호화
- AWS Management Console 또는 최신의 AWS SDK 또는 CLI와 함께 사용
"There is no compression algorithm for experience"
- Andy Jassy (CEO, Amazon) -
'Linux > AWS' 카테고리의 다른 글
| AWS EC2 Load Balancer 공부 (0) | 2022.02.07 |
|---|---|
| AWS EC2로 WordPress 만들기 (0) | 2022.01.27 |
| AWS 온라인 컨퍼런스 정리4 (0) | 2022.01.20 |
| AWS 온라인 컨퍼런스 정리3 (0) | 2022.01.20 |
| AWS 온라인 컨퍼런스 정리1 (0) | 2022.01.20 |
