INDEX
: 어떤 데이터가 어디에 있다는 주소록 같은 개념
: WHERE절에 오는 조건 컬럼이나 조인 컬럼 등에 만들어야 함
(몇 가지 특별한 경우에는 SELECT에 있는 컬럼에 생성하기도 함)
: 인덱스를 사용하려면 WHERE절의 조건을 절대로 다른 형태로 가공해서 사용하면 안됨
B-TREE 인덱스 생성 원리
: 전체 테이블 스캔(Table Full Scan) → 정렬(Sort) → Block 기록

: 인덱스를 생성하라고 명령을 실행하면 위 그림의 1번 과정에서 제일 먼저 해당 테이블의 내용들을 전부 다 읽어서
메모리로 가져옴
: 인덱스 만드는 동안 데이터가 변경되면 문제가 되므로 해당 데이터들이 변경되지 못하도록 조치를 한 후
위 그림 2번 과정처럼 메모리(PGA의 Sort Area)에서 정렬을 하게 됨
: 만약 PGA 메모리가 부족하게 되면 임시 테이블 스페이스(Temporary Tablespace)를 사용해서 정렬하게 됨
(이 과정이 시간이 정말 많이 걸리는 과정)
: 3번 과정으로 메모리에서 정렬 과정이 모두 끝난 데이터들은 인덱스를 저장하는 파일의 블록에 순서대로 기록
: 오라클에서 쿼리를 빨리 수행되게 하려면 가능한 한 정렬을 줄여야함
(그만큼 정렬이 쿼리 수행 속도에 악영향을 많이 준다는 뜻)
인덱스 구조와 작동 원리(B-TREE 기준)

: 테이블은 컬럼이 여러 개이고 데이터도 정렬 없이 입력된 순서대로 들어가 있음
: 인덱스는 컬럼이 Key 컬럼과 ROWID 컬럼으로 이루어져 있음
Key 컬럼 - 인덱스를 생성하라고 지정한컬럼 값
ROWID - 데이터가 저장되어 있는 주소
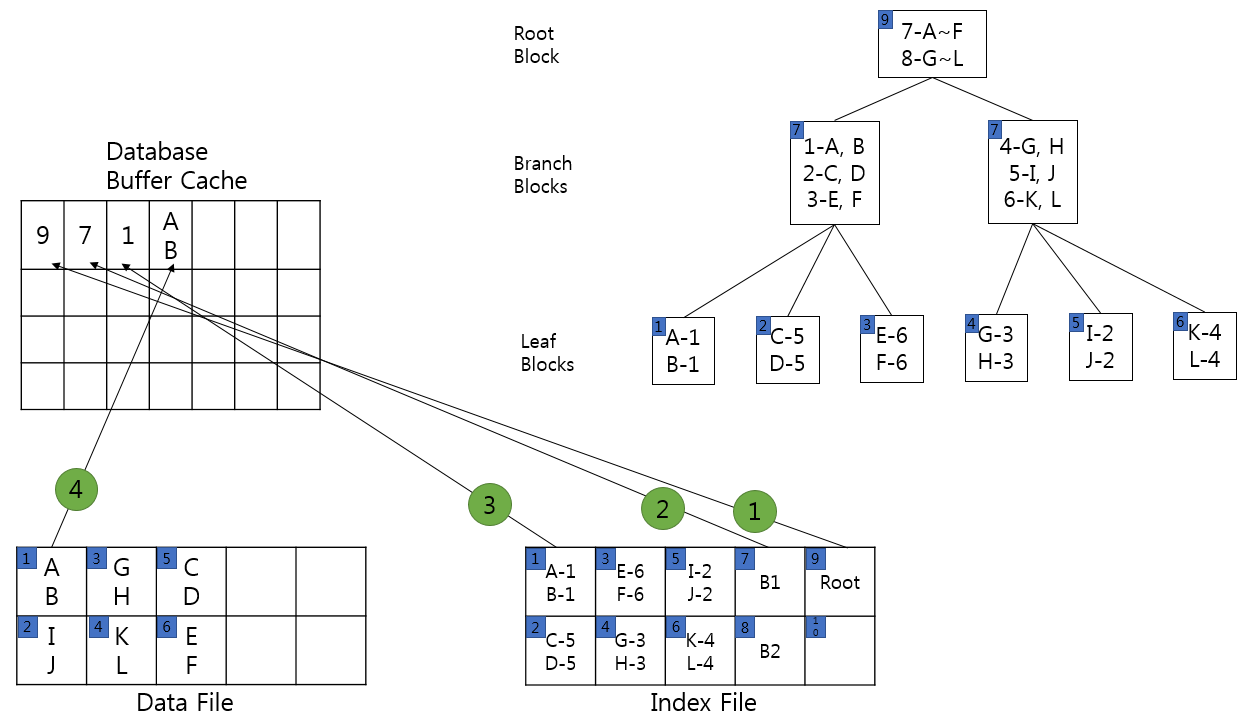
: 사용자가 A값을 조회하는 쿼리를 실행했을 때
1. 위 오른쪽 그림에서 가장 위에 있는 Root Block을 Index File에서 Database Buffer Cache로 가져와서 사용자가 찾는
A가 들어 있는 블록에 대한 정보를 찾습니다. ( 7 - A~F )
2. 두 번째로 Index File에서 7번 블록을 다시 Database Buffer Cache로 복사해서 A가 들어 있는 다음 블록 정보를
찾습니다. ( 1 - A, B )
3. 위 그림에서는 Index File에서 1번 블록이므로 다시 Index File의 1번 블록을 Database Buffer Cache로 복사해서
데이터 파일에서 A가 어떤 블록에 들어 있는지를 찾아 냅니다.
4. Index File의 1번 블록에 보면 A-1, B-1이라는 정보가 있는데, 이 정보가 Data File의 실제 블록 정보입니다.
그래서 Data File에 1번 블록을 Database Buffer Cache로 복사해서 A를 찾아서 사용자에게 주면 끝이 납니다.
: 경우에 따라서는 인덱스를 사용하는 것보다 인덱스를 안 쓰는 것이 성능에 더 좋을 수도 있습니다.
: 여러 건의 데이터를 조회할 경우에 인덱스를 사용할 경우에는 한 번에 하나의 블록만 읽을 수 있다.
: Single Block I/O - 1번에 1개의 블록만 읽어서 메모리로 가져오는 것
: Multi Block I/O - 인덱스를 쓰지 않고 디스크에서 여러 블록을 한꺼번에 메모리로 가져오는 것
B-TREE 인덱스
: 생성 순서 = Leaf Block → Branch Block → Root Block
: 찾는 순서 = Root Block → Branch Block → Leaf Block
: B-TREE에서 B란 Binary란 의미도 있고 Balance란 의미도 있음
(Root Block을 기준으로 왼쪽과 오른쪽에 들어있는 데이터의 Balance가 맞을 때 성능이 가장 좋다
: 데이터의 값의 종류(Cardinality)가 많고 동일한 데이터가 적을 경우에 사용하는 인덱스
: OLTP(Online Transaction Processing) 환경에서 많이 사용

: UNIQUE INDEX
- Key 값에 중복되는 데이터가 없다는 뜻 (중복된 데이터가 들어올 수 없다)
- 향후에 중복값이 입력될 가능성이 있는 컬럼에는 절대로 이 인덱스를 생성하면 안됨
- 일반 인덱스보다 속도가 빠름
CREATE UNIQUE INDEX 인덱스명
ON 테이블명(컬럼명 [ASC|DESC]);
: NON-UNIQUE INDEX
CREATE INDEX 인덱스명
ON 테이블며(컬럼명 [ASC|DESC]);
: Function Based INDEX (FBI - 함수기반 인덱스)
- 연산을 수행해서 인덱스를 만들 수 있음
- 임시적인 해결책은 될 수 있어도 근복적 처방은 아니기에 아주 조심해야함
- 쿼리의 조건이 변경된다면 인덱스를 다시 만들어야함
- 기존 인덱스를 활용할 수 없음
CREATE INDEX 인덱스명
ON 테이블명(함수);
--ex)
CREATE INDEX idx_test
ON test(num + 1);
: DESCENDING INDEX (내림차순 인덱스)
- DESC INDEX는 인덱스를 생성할 때 내림차순으로 인덱스를 생성하는 것을 말함
- 주로 큰 값을 많이 조회하는 SQL에 생성하는 것이 좋음
CREATE INDEX 인덱스명
ON 테이블명(컬럼명 DESC);
: Composite INDEX (결합 인덱스)
- 인덱스를 생성할 때 두 개 이상의 컬럼을 합쳐서 인덱스를 만드는 것을 말함
- 주로 SQL 문장에서 WHERE절의 조건 컬럼이 2개 이상 AND로 연결되어 함께 사용되는 경우에 많이 사용함
- 해당 데이터를 찾을 때는 두 개(혹은 이상)의 컬럼을 동시에 만족하는 블록을 검색함
CREATE INDEX 인덱스명
ON 테이블명(컬럼명1, 컬럼명2, ...);
BITMAP INDEX
: 데이터 값의 종류가 적고 동일한 데이터가 많을 경우 사용
: 데이터의 변경량이 적거나 없어야 함
(새로운 데이터가 들어오게 되거나 변경이 되면 기존에 만들어져 있던 모든 Map을 다 고쳐야 하는 일이 생김)
: 주로 OLAP(Online Analyical Processing) 환경에서 많이 생성함
: 블록 단위로 Lock을 설정하기 때문에 같은 블록에 들어 있는 다른 데이터도 수정 작업이 안되는 경우도 생김
CREATE BITMAP 인덱스명
ON 테이블명(컬럼명);
인덱스의 주의사항
DML에 취약하다
: DML이 발생하는 테이블은 인덱스를 최소한으로 작게 만들어야 합니다.
: INSERT 작업 시 인덱스에 발생하는 현상
- 인덱스가 생성되어 있는 컬럼에 새로운 데이터가 Insert될 경우 INDEX Spilt 현상이 발생할 수 있고
이 현상으로 인해 Insert 작업의 부하가 심해질 수 있습니다.
- INDEX Spilt = 인덱스의 Block들이 하나에서 두 개로 나누어지는 현상
오라클이 자동으로 진행해주지만,
완료되기 전까지 다음 데이터가 입력이 안되고 계속 진행중인 상태로 대기하고 있어야 합니다
: DELETE
- 테이블은 데이터가 delete가 되면 지워지지만,
INDEX에서는 delete가 되지 않고 해당 인덱스에서는 데이터가 사용 안된다는 표시만 해둡니다.
(테이블에서는 데이터가 지워지지만, 인덱스에서는 데이터가 안 지워진다는 의미)
: UPDATE
- 인덱스에는 UPDATE라는 개념이 없습니다.
- UPDATE가 발생할 경우 인덱스에서는 DELETE가 먼저 발생한 후 INSERT 작업이 발생하게 됩니다.
즉, 인덱스는 더 이상 데이터를 추가/변경 하지 않을 시점에 많드는 것이 가장 좋다.
(Index Spit을 발생 안시키기 위해서)
타 SQL 실행에 악영향을 줄 수 있다
: 옵티마이저가 실행 계획을 세울 때 기존에 없었던 인덱스가 갑자기 테이블에 생기면 더 최근에 만들어진
인덱스가 더 좋을 것이라고 생각해서 잘 되고 있던 실행 계획을 바꾸기 때문입니다.
인덱스 조회하기
set line 200
col table_name for a10
col column_name for a10
col index_name for a20
SELECT table_naem, column_name, index_name
FROM user_ind_columns
WHERE table_name = "테이블명(대문자로)";
-------------------------------------------
SELECT table_name, index_name
FROM user_indexes
WHERE table_name="테이블명(대문자로)";
사용 여부 모니터링 하기
: Oracle 9i 버전부터 사용 유무를 파악하는 기능을 제공
: 모니터링 시작하기
ALTER INDEX 인덱스명 MONITORING USAGE;: 모니터링 중단하기
ALTER INDEX 인덱스명 NOMONITORING USAGE;: 사용 유무 확인하기
- 자신이 만든 인덱스만 할 수 있다
SELECT index_name, used
FROM v$object_usage
WHERE index_name = '인덱스명(대문자)';
- 만일 sys 계정으로 모든 인덱스의 사용 유무를 조회하고 싶다면 DBA가 뷰를 생성해서 조회하면 됨
CREATE OR REPLACE VIEW V$ALL_INDEX_USAGE
( INDEX_NAME,
TABLE_NAME,
OWNER_NAME,
MONITORING,
USED,
START_MONITORING,
END_MONITORING)
AS
SELECT a.name, b.name, c.name,
decode(bitAND(c.flags, 65536), 0, 'NO', 'YES'),
decode(bitAND(d.flags, 1), 0, 'NO', 'YES'),
d.start_monitoring,
d.end_monitoring
FROM sys.obj$ a, sys.obj$ b, sys.ind$ c
sys.object_usage d, sys.user$ e
WHERE c.obj# = d.obj#
AND a.obj# = d.obj#
AND b.obj# = c.bo#
AND e.user# = a.owner# ;
INDEX Rebuild하기
: 인덱스는 한 번 만들어 놓으면 영구적으로 잘 작동하는 것이 아니라 생성 후에도
꾸준히 관리를 해 주어야 좋은 성능을 기대할 수 있다.
: 테스트 테이블 생성(값은 PL/SQL로 1~10000 넣음)

: 상태 조회
ANALYZE INDEX 인덱스명 VALIDATE STRUCTURE;
SELECT (del_lf_rows_len / lf_rows_len) * 100 BALANCE
FROM index_stats
WHERE NAME='인덱스명(대문자)';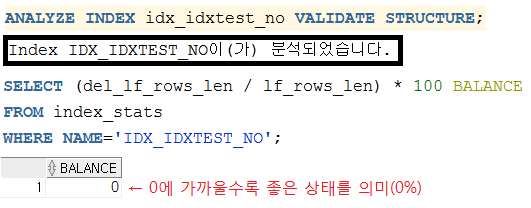
: 데이터를 4000건 지운 후 인덱스 상태 조회

: Rebuild 작업으로 수정
- ONLINE옵션은 REBUILD 작업 중에 DML을 사용 가능하게 해주지만 전체적인 성능이 많이 떨어짐
ALTER INDEX 인덱스명 REBUILD [ONLINE];
Invisible Index
: 11g부터 인덱스를 실제 삭제하기 전에 '사용안함' 상태로 만들어서 테스트 해 볼 수 있는 기능을 제공
: INVISIBLE 옵션은 옵티마이저가 실행 계획을 세울 때 해당 인덱스가 없다고 알려주는 의미
그러나 DML 작업 시 인덱스 내용은 계속 반영되므로 인덱스가 지워진 것은 아닙니다.
ALTER INDEX 인덱스명 [INVISIBLE/VISIBLE];
ROWID
: 오라클에서는 데이터 주소를 주소라 표현하지 않고 ROWID라고 부릅니다
: 어떤 데이터의 ROWID를 알고 있다는 것은 해당 데이터의 저장된 위치를 정확하게 알고 있다는 의미
: 데이터들의 ROWID 정보를 별도의 세그먼트에 넣어서 저장하고 관리하는데, 이 세그먼트를 인덱스라고 함
| 종류 | Oracle 버전 | 크기 |
| 제한적인 ROWID | 7버전까지 | 6 bytes |
| 확장된 ROWID | 8버전부터 | 10 bytes |
: ROWID 쿼리문으로 조회
SELECT ROWID FROM 테이블명;
'DataBase > OracleDB' 카테고리의 다른 글
| Oracle 11g ex 설치 (0) | 2020.09.14 |
|---|---|
| Oracle 11g ex 삭제 (0) | 2020.09.14 |
| DML (0) | 2020.09.04 |
| DDL 명령과 딕셔너리 (0) | 2020.09.04 |
| Constraint (제약 조건) (0) | 2020.09.04 |
